Existing solutions
Component-based software and Compound Documents
In the late 60's, the increase of difficulties in managing large software systems was named as “the software crisis”. To cope with the new challenges of Software Engineering, some researches devised solutions based on 'software components', which are “modules” of software that can be connected loosely to others to solve complex problems. Pipes and filters of the Unix operating system or the invention of the Objective-C programming languages are first examples of this approach. However, these techniques are oriented to programmers only.
Besides, in the early 80's, the Xerox's Star system introduced the concept of WYSIWYG (What You See Is What You Get), proposing a graphical representation of all information objects to allow users to select and manipulate them with their related tools. The software framework was named as 'ViewPoint', wherein the documents were built as a composition of pieces of information, so they were defined as 'compound documents'. Today, this concept also applies to the case of simple applications that can embed other types of data inside their native data through 'copy & paste' procedure, such as a text editor that can embody an image in the text document.
These core ideas have been adopted by current software systems, although their implementation diverged from the original spirit of a pure compound-document component-based software, i.e., from a true object-based system. In next sections, we'll see an overview of the subsequent systems that adhered more tightly to such core idea.
Early systems
In 1982, Carnegie Mellon University, with support from IBM, started developing the 'Andrew User Interface System', which allows for more dynamic manipulation of information objects. Specifically, documents can incorporate any type of object, and the system allows new types thanks to a mechanism of extension of their computer code. The following illustration shows and example of a compound document side by side its associated software components:
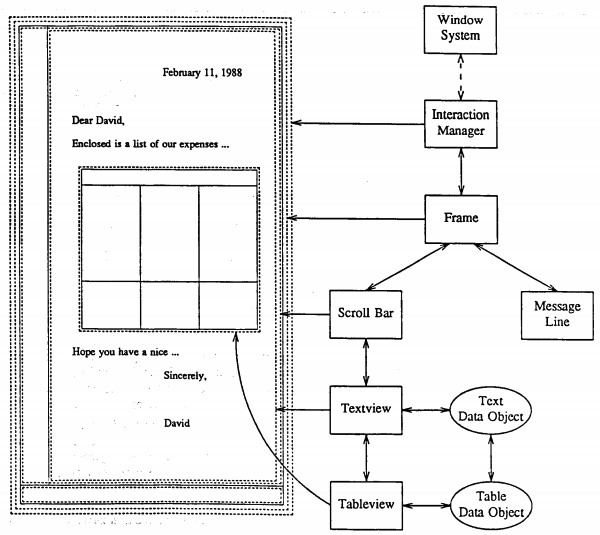
Other remarkable systems that also implemented these approaches were the Dr. Ken Sakamura's 'BTRON' system (1984) and the Hewlett-Packard's 'NewWave' (1988). Despite all these systems were real pioneers in the realization of the object-based interfaces and despite they relatively succeeded in their contemporary society, they are now abandoned or transformed into specialized components of other systems.
Microsoft's OLE
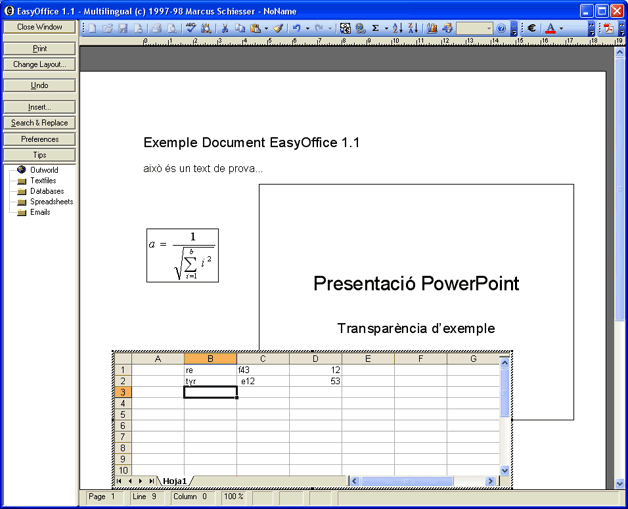
In 1990, Microsoft introduced 'OLE' (Object Linking and Embedding), a software architecture that allows to insert a piece of data produced with one program into the content managed by another program. The object can be referenced with a link that points to the original place of its data (typically, a portion of a file), or can be embedded into the data structure of the document that will hold the inserted object (another file). This approach enables to perform what is called “in-place edition”. In this manner, the original data is not lost when transported to other applications, and the manipulation of the data is independent from the environment where the object is inserted in.
The following illustration shows an example of a compound document made of OLE objects, managed by a “document composer” application called 'EasyOffice' (by Marcus Schiesser):
Apple's OpenDoc
In 1992, Apple joined with IBM and WordPerfect (and later on with other companies) in a partnership to offer an alternative to OLE, which was named as 'OpenDoc'. The general ideas behind OpenDoc are essentially the same: a software architecture were the user's documents are composed of inner objects so-called “parts”, where each part can be edited in-place by a suitable editor. However, the working principle of OpenDoc that clearly differs from OLE is that the software components responsible for visualizing and editing each part can run independently of any particular application; one generic program called “document shell” acts as a generic framework to create and edit any OpenDoc document.
Therefore, the OpenDoc technology is much more document-centric in the sense that it exposes more clearly the hierarchical construction and editing of data objects than the OLE technology, which is more application-centric because the users still work with the mental model based on computer applications that act as data editors.
The following illustration shows two states of the editing of an OpenDoc document, where it can be appreciated that menus and toolbars change accordingly to the type of the selected data object:

Nevertheless, OpenDoc did not survive the market dynamics, in part because there were very few third-party developers committed with the new software architecture, in part because Apple decided (in 1997) to cancel the project and concentrated its efforts in other fields, such as integration with Internet.
Microsoft's ActiveX
Microsoft also focused on Internet and, in 1996, introduced 'ActiveX', an adaption of the OLE components for web pages. Today, OLE and ActiveX are still in use because Microsoft required during a long period of time (more than 10 years) that any software package aimed to be certified by the Microsoft corporation must adhere to the protocols and interfaces stated by these architectures, although in practice the majority of component-based implementations are mostly constrained to the interoperability with Microsoft Office (for OLE 2.0) or Internet Explorer (for ActiveX controls).
Other systems
There are many patents for systems that handle databases of information objects as well as the software components that deal with such objects, for example:
-
U.S. Patent No. 5,303,379: “Link Mechanism for Linking Data between Objects and for Performing Operations on the Linked Data in an Object Based System”, by Khoyi et al. (Wang Laboratories, Inc., 1992),
-
U.S. Patent No. 6,606,633: “Compound Document Management System and Compound Document Structure Managing Method”, by Tabuchi (NEC Corporation, 1999),
-
U.S. Patent No. 7,376,895: “Data Object Oriented Repository System”, by Tsao (Wuxi Evermore Software, Inc., 2002).
In the other hand, there are several component-based software frameworks that are currently in use:
-
CORBA Component Model from the Object Management Group (1991),
-
Component Object Model (COM, 1993) from Microsoft, and its distributed version DCOM,
-
Java beans from Sun/Oracle (1999),
-
KPart, the software component technology introduced in KDE 2.0 (2000),
-
etc.
Finally, we want to mention other approaches which have poor relation with the core ideas we are discussing, but also interesting since they try original ways to manage user information different from the typical structure (OS, apps and files):
-
the Semantic Web movement led by the World Wide Web Consortium (W3C), to organize and process Internet data in an “intelligent” manner,
-
the Archy system by Jeff Raskin, to handle data only with system commands, text leaping and zoomable interface,
-
the TheBrain software by TheBrain company, to organize user information in a conceptual map style.
The missing solution
Despite all the literature and existing methods that implement object-based information processing, we always find them inadequate mainly because one or several of the following reasons:
-
because they store the content of the objects into files and folders, instead of using a database (preferably an object-oriented one),
-
because they are intended for programmers, so end users cannot access data through symbolic (graphical) interfaces but through highly specialized procedures,
-
because they are too application-centric approaches, so the user still must handle a bunch of different applications for several purposes,
-
because they are awkward to configure or adapt to the specific needs of end users.
Therefore, our goal is to create a true information object system stored in an object-oriented database and controlled through software components that the user could install or de-install with easy. Ultimately, we believe that end users can manage all their information in an integrated database without having to learn specific programming languages or data management commands. So, please continue reading our “Proposals” section to judge by yourself if our ideas can lead to such an “utopian” system.