User's handicaps
Handicaps overview
Despite the opportune advances in software usability, the majority of users still suffer many difficulties when trying to do common tasks with current systems. From our point of view, all these obstacles are strongly related to two general handicaps:
-
an enormous number of different applications, being those applications bloated with a significant number of actions and options,
-
an information structure based on files and folders, which makes it difficult to organize the contents for later retrieval, as well as incompatibilities due to file formats.
These two general handicap lead to a more fundamental one:
-
the lack of information coherence, due to the dominant role of application functionality over the data structure, and due to the arbitrary dissemination of the data into files, so it is almost impossible to relate different pieces of information stored in different files.
Growth of applications
The number of computer applications grown up exponentially in the 60's, 70's and 80's. The number of web applications started to grown up exponentially in the 90's. The number of mobile applications is still growing up exponentially from the 2000's. The next plot is an estimation of the total amount of apps in each group.
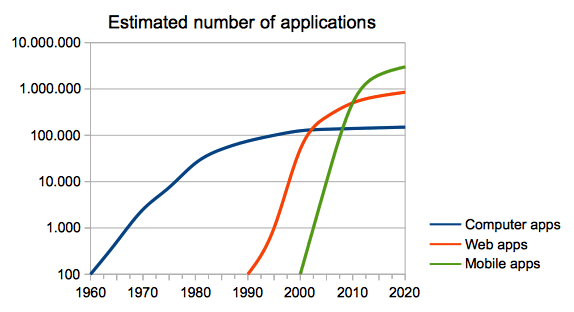
At long term, the majority of applications fall in disuse because only a reduced set of them become popular. Hence, the number of apps in each group tend to stabilize when the market gets saturated and also when it focuses into another system. Moreover, the total maximum in each group is higher than the previous one in almost one order of magnitude (note the logarithmic scale), because the number of potential users also increases in time.
Today, users can choose among millions of different applications. We think that this is a source of confusion: which app should you choose for doing specific tasks? Besides the effort needed to make the decision, it is possible that the info created with that app must be redone in order to share it with other people that do not work with the same app or platform. Therefore, what is usually seen as an advantage may lead to a lot of nuisance.
Complexity of applications
Researchers and Industry have been putting a lot of effort in making software systems as simple to use as possible. However, different tasks currently require different programs or even different operating systems, browsers or mobile devices. Indeed, users need at least one program for each type of information they may want to deal with (text, tables, presentations, formulas, images, videos, etc.). Therefore, we users spend a lot of energy in learning and handling applications, to the detriment of our inherent aim of creating and reviewing information.
Computer applications tend to be very rich in tools and options, which increases software complexity. GUI interfaces ease the learning and manipulation processes, as well as the fact that the design of menus and actions follow some sort of guidelines that provides for a certain degree of homogeneity (File, Edit, Format, Insert, Window, Help, etc.). Nevertheless, some applications may become so huge that the user must take some courses to be able to deal with it (e.g., Adobe's Photoshop). Arguably, most users only use 10% to 20% of the total set of possibilities of complex software, but the remaining “useless” options are frequently perceived as a very positive factor, so developers keep adding more features to the never-ending improvement of their products.
Web applications are more specific than computer-based apps, since their inherent User Interface techniques discourage deeply hidden options such as dialogs or sub-menus. Mobile apps have even more restrictions due to small screens and touch-based input, so they have even less options than web apps. The net result of this reduction is that mobile apps are easier to use than web apps, which in turn are easier to use than computer apps, despite the fact that mobile and web apps present significantly less homogeneity between each other than computer apps.
Obviously, mobile and web apps can do less things than computer apps, and therefore we may need several of those apps to perform the same tasks than in a single computer app. Consequently, users end up with many different and inconsistent ways to handle their information.
Data structure
In the early 60's, it became obvious that information should be treated in a consistent manner, so scientists invented mathematical models to represent and handle information efficiently, that is, they created 'database managers'. Today, every system for highly efficient data processing (business, research, administration, etc.) is supported by the available database models ('relational', 'hierarchical', 'object oriented', etc.), and no serious designer would rely on files and folders to store such precious data. During more than 50 years, databases have demonstrated largely their multiple advantages in front of a file-based data organization in terms of efficiency, concurrency, resilience and reusability (among others).
On the other hand, productivity applications like office packages and graphical design suites have stuck into the file system model. Therefore, the majority of user information (texts, images, tables, plots, audio, video, etc.) ends up stored in files, which represent that info with a specific codification, known as the 'file format'. The following “word cloud” shows 573 file formats that are currently in use, magnifying the size of the letters according to its significance:

(source: FileFormat.info)
Since there are many file formats to choose, one of the most painful inconvenience is the incompatibility between file formats and applications, specially when trying to share information with other people. Consequently, there is a need for specific apps that can translate file formats, which introduces a superfluous task. Besides, the translation may result in data loses.
Further, the hierarchical structure of directories (so-called 'folders') provides the user with a completely arbitrary manner to organize the files, which require lengthy manual processes to classify and perform later retrievals of information. This leads to the need of specific tools for automatic searches by file name, creation or modification date, type (format) or textual content, but even with such mechanisms the data can get finally lost.
Despite all problems related to files and folders, this approach have persisted since it appeared in the late 50's until nowadays with actually no changes in its concept, mainly because people is extremely used to that concept.
Inconsistent info handling
From our point of view, the most questionable characteristic of current IT systems is their application-centered approach, which means that the user must think in terms of the available application tools and options. On the contrary, what users do is to create, update, transfer, share, query and delete information, which is much more well fitted by a document-centered approach, where users can think in terms of data structure and content.
One example of the downsides of application-centered approach is that different applications treat the same source of data in different ways. For example, text edition is not equally handled in a word processor, in a spreadsheet application, in a presentation composer or in an e-mail dealer, even in the case that all these programs are part of the same software package.
Other application-centered drawbacks appear when composing a document with different types of information. For example, if we want to create a document with text an illustrations, we may choose a word processor to edit the text and to compose the main document, and a drawing application for creating the lines and other graphical elements of illustrations. Obviously, we will use the 'copy & paste' procedure to insert the illustrations into the textual document, but it may happen that not all information contained in the original draw is fully recorded inside the document; for example, the geometrical elements may be converted into a pixel-based image. In this case, when we need to change the illustration, we must re-edit it with the drawing application (if we saved it into its specific file) and repeat the copy and paste procedure to update the appearance of the image inserted in the document.
In the aforementioned example, there is an additional problem related with the file-based storing of information. Since we want to be able to modify the drawings in the future, we are obliged to keep record of those drawings in specific files, separate from the document file. This means that we must manually take care of data synchronization; otherwise the content of both “copies” of the same illustration will eventually diverge. If the same illustration is used in other documents, the problem of future updates gets acute, since the file system does not keep track of all data relations between files. Moreover, when sharing our information with other people we must remember to pass all related files to them, or they will not be able to edit the whole information.
Other file related problems arise when diverse situations of data relations appear, that will efficiently solved with a database approach. In the next page 'Existing solutions' we describe some document-centered approaches that tried to solve the aforementioned problems. In the next section “Proposals” we describe our own info-centered approach that overcomes some weakness of the existing systems.